

mewsings, a blog

Tuesday, January 31, 2006
The Data Movement
Data. Movement. Toss in some musings about differences between the sexes and that will do for today.

<CYA>
Gender can be a divisive subject, and I want to be clear that I have no expertise in the field of gender studies, nature vs. nurture, or how brains differ. One of my readers from down under tells me that feminism is a sensitive subject there due to a lack of full-time jobs for men over forty right now. Apparently there has been some reverse discrimination. I do not think I have been discriminated against in my career at all. Unlike some of you, I have never even been in an all-male meeting. But I have taken note of statistics indicating a downward trend of women in computing and have seen a lack of female computer science majors in at least one college in the USA. I decided to weave this topic into my mewsings today, giving possibly a new angle to the otherwise tired data vs. process topic.
</CYA>
It's time to put a definition of data on the table, data as in data modeling and database, and even the good old term data processing.
Data: encoded propositions, a combination of form and meaning; accurate data are facts.
Accurate data are facts. Ho Hum.
Ho hum. Here's a fact: I'm in my forties. If you capture that fact as data today and then present it thirty years from now, it will be as accurate as if I were to attach a high school picture to this blog today. Alas, data changes. It can also be disseminated. Data with movement—now that's much more interesting to me.
I started in data processing with a summer job during college in 1977. I had pounded the pavement for a job. If I had not gotten this job at the last minute, I would have started as a waitress the following Monday. I had memorized the menu already, but was petrified, knowing I was not really waitress material. But I also knew I didn't want to return to being a nurse's aide in a nursing home ('73-'75) or a maid in a Holiday Inn (Maid of the Month, July 1976).
My qualifications for this job programming COBOL on a Pr1me 300 were that I had taken the equivalent of one semester course covering COBOL, BASIC, and Fortran (two half courses, to be precise). The person hiring me said the other qualification I had was that I was majoring in mathematics and to him that meant that I was smart.
While it is impossible to know what would have happened under different circumstances, I am as sure as I can be that I would not major in computer science were I to enter college today. Often a computer science major is required now for those entering software development professions. I can think of no reason why I would have chosen to major in a machine. I have even avoided joining ACM until last year when I wanted to download more papers than would make sense on a pay-per basis. I didn't like Machinery in the name. I have no interest in machinery, much less an association for such machinery.
What is the percentage of women in the car industry compared to the travel industry? What is the percentage of women in computer science compared to those who were once in that now-called-something-else profession of data processing? Some think the decline is a failure of the women's movement or, perhaps, of women. But I see it as a success with the women's movement in that girls know they have options. It is a failure of our discipline to appeal to these girls as it once appealed to the girl I was when it captured me.
- The percentage of women receiving bachelor-level degrees in computer or information sciences has declined from a peak of 35.8 percent in 1984 to 26 percent today.
- Among the science and engineering workforce, computer science is the only area where women's participation has declined since 1993. (umbc.edu/cwit/computer_mania.html)
I'm not interested in bases of data. I'm interested in uses of data.
I like movement and connections. To me, data processing is like travel, like movement. Databases are more like computers and cars. I'm not interested in bases of data. I'm interested in uses of data, in data movement. I went on for a master's degree in pure mathematics, not applied mathematics or science. So there is little appealing to me about a discipline called Computer Science. I'm drawn to it about as much as to the term Database Management System.
That is the great distinction between the sexes. Men see objects, women see the relationships between objects. (John Fowles)
Of course this is a generalization. I do like language and data. But I would say that I like the relationship of language and data within systems that include people. I like connections, change, impact, and movement. Am I really about to blame some part of the decrease in women in computing on the change from a focus on data processing and terms implying movement to a focus on computer science and nouns of data, DBMS, tables, domains, constraints, and objects? Yup. (Do you like how I also just tossed the OO folks into the same bucket as the RM folks?)
Thinking in terms of static data, without concurrently addressing changes to the shape, content, and distribution of that data, the use of and interactions with the data, the movement of data, is simply not compelling. These encoded propositions exist in fluid, changing systems, not as data in a vacuum.
Put the processing back with the data, please.
If you take a girl today similar to the girl pictured here, with similar interests and aptitudes, my hypothesis is that she will not end up in computer science. That's what happens when the women's movement meets a discipline defined in terms that suggest no movement. Girls rarely choose to focus on objects or data. Let's tap into the data movement and put the processing back with the data, please.
Tuesday, January 24, 2006
The Naked Model

Strip the term relational from relational model and you have an unadorned model. So as not to confuse this with other possible meanings, we should be more precise. This model is typically termed a data model. A data model is employed in the design, construction, and maintenance of computer software systems.
The goal of this article is to get us to a common understanding of the term data model while also giving more indication of where these mewsings are headed. Before zeroing in on the meaning of data model, let's look at some similar terms used in software development that are NOT the same. For example, is this data model minus the relational adjective a...
...Conceptual Data Model (CDM)? Nope.
The CDM results from analyzing an area to be automated, capturing requirements, and communicating these between those who know the subject areas and those who will develop a software system. While the CDM can be back-of-a-napkin informal, there are many techniques for adding rigor, including the use of Entity-Relationship or UML Class Diagrams.
...Logical Data Model (LDM)? Nope.
This is the one that concerns me. Please don't confuse the naked data model with the logical data model, OK? When talking about a particular system, an LDM might be called the data model by some. However, the LDM is different from the term data model being discussed in this blog, so when I write data model sans adjectives, I am not referring to an LDM. The LDM results from structuring a specific CDM and communicating that structure to the computer.
...Physical Data Model (PDM)? Nope.
Only those writing the low-level database software need to know anything about the physical model, in theory (knowing grin goes here). Pretty much the only time you will hear me talk about the physical data model is if I am saying that I am not talking about the physical data model.
Each of these three possible glossary entries is related to a particular problem space being modeled for incorporation in a computer system. The data model we are talking about is more abstract. Data models such as the RM have implications for all LDMs.
Now that we know what our data model is not, let's turn our attention to what it is. The Relational Model (RM), introduced in an earlier blog, is a sweet, tight, mathematical model based on set theory and predicate logic. While you might have a hint that I'm putting the RM on trial over the course of these mewsings, I really do appreciate predicate logic and adore set theory. I applaud the cleverness in modeling data with both set theory and predicate logic. It can be quite helpful. For example, if we organize data and prepare query languages aligned with first order predicate logic, we can prove that our queries will return accurate results with respect to the data, in a finite amount of time. Also, if we choose a mathematically simplified data model, we can implement a mathematically simplified query language.
In addition to appreciating mathematics, I also like religion. But I hope to debunk some of the RM religion that has come along with the application of these mathematics to data. The current use of the RM has been pervasive-enough in the industry that it will take me some time to lay out a case. If all goes well, I plan to have closing arguments sometime before the end of 2006. I will also admit that while I think I have a good case, I don't have it all formed into words in my head just waiting to hit paper. Writing in blog-sized units should help me refine and crystalize my thinking. I hope that you, the jury, enjoy taking the journey through the evidence with me.
I would like to enter into evidence the Information Principle as Exhibit A. I will use a quotation from C. J. Date who is quoting E. F. (Ted) Codd. Both of these men have been at the center of relational data modeling.
Exhibit A: The Information Principle
"The Information Principle (which I heard Ted refer to on occasion as the fundamental principle underlying the relational model) [is]...
The entire information content of a relational database is represented in one and only one way: namely, as attribute values within tuples within relations." (Date, Edgar F. Codd, A Tribute, www.sigmod.org/codd-tribute.html)
A data model is related to the representation of data
Tuck this point away: a data model is related to the representation of data. Now let's move on to a definition of a generic data model, using Date to rephrase Codd.
Codd defines a data model in a 1980 paper Data models in database management. By his definition a data model consists of a collection of data structure types, operators that can be applied to instances of these types and consistency rules that define valid states for the data.
Objects, operators, and, effectively, rules for assignment…Hmmm… If we were to implement a data model what would we have? Let's take a look at a recent definition of data model from Date.
A data model is an abstract, self-contained, logical definition of the objects, operators, and so forth, that together constitute the abstract machine with which users interact. The objects allow us to model the structure of data. The operators allow us to model its behavior. (C. J. Date, An Introduction to Database Systems, Addison Wesley, 8e, 2003, p 15-16)
The implementation of a data model is a programming language
I conclude from this that the implementation of a data model is a programming language, whether a general purpose programming language or not. Also, each programming language provides an implementation of a data model or perhaps more than one. Put another way, a data model is an abstraction of a programming language or programming sublanguage.
Now that we have some clarification of the term data model, I will make a claim that is likely agreeable to readers as I have never heard anyone argue otherwise. The RM is not necessary. It is not necessary for developing software solutions, maintaining large shared databases, or any other purpose in the world of software development. Any software solutions that can be developed while employing the RM could be written without it, using other data models. I will follow this up in a future blog by showing that the RM is not sufficient for developing and maintaining data-based software. Once we are all on the same page that the RM is neither necessary nor sufficient, we can look at what the purpose of the RM is and discuss its comparative usefulness.
My beef with the RM is related both to normalization theory as taught in colleges and universities, discussed in the Is Codd Dead? blog and to the way the RM, or parts thereof, are used in the practice of software development and maintenance today. It shapes the thinking of software developers in ways that are often not the most effective.
The RM is not necessary
And, by the way, if you are thinking that the RM need not be obvious in a developer's programming language but could be hidden behind the scenes, then my work is done. That would mean that no computer language would need to use the Information Principle, and neither you nor I would need to use the RM as a data model. We can use any programming language that does not represent itself as an implementation of the RM to employ an alternative data model. Did I mention that the RM is not necessary?
Monday, January 16, 2006
Who Ordered the Ripple Delete?

I have dabbled a bit in digital video editing, inserting and deleting frames, for example. If I select frames and hit the keyboard Delete, the frames are removed, but a gap remains where they once were. That is often not what I want. Enter: the ripple delete. I'll admit to having a slight shiver of delight when I perform a ripple delete. Behind the scenes it not only deletes the frames, but moves frames up to cover the gap. Editors who have worked with physical film and a razor blade must be ecstatic.
The frames of a video are similar to any other ordered list of data. This ripple delete feature can be added to any software application that shows users an ordered list. Product features are not determined by a particular underlying database data model. However, I am using the feature of an ordered list to set the stage for investigating the meaning and implications of chosing one or another data model, with a definition for "data model" coming in the next blog. If the same features can be implemented in software whether using the Relational Model (RM) or not, why might a team choose not to employ the RM?
Rather than avoiding ordered lists, you start seeing how common they are when you free your mind of the RM.
Let's turn to an example of a simple ordered list. If I were not such a novice with AJAX, I might have provided an example of a ripple delete on a list, but my working example should help with the illustration none-the-less. Also, please forgive my burst of saccharin marketing spin, but because of using
- tag-delimited strings
- NF2 and
- two-valued logic (2VL)
throughout the entire development process, I'm naming this style of development End-to-End AJAX or maybe N2N AJAX. You can gag now, but it isn't like naming JavaScript after Java, given that AJAX really is used at the front-end.
Using the example from the last blog, I'll add a requirement for the e-mail addresses to be ordered. Someone using the database would send either bulk or individual e-mails first to the first address and if that bounces, then to the second. I can place an ordered list in my logical model and then in my implementation. That way I can enjoy use of the ordered list without managing a separate ordering attribute myself, without having to remember to sort the output, nor writing my own ripple delete process.
See this example as a hint at developing using End-to-end AJAX. While a ripple delete is not a standard feature of an RDBMS, it is part of the charm of MV databases. So, the e-mail list is defined as an ordered list to our database. AJAX is used on the front-end, including xhtml, css, and JavaScript. The output comes from a query of the database without procedures to reshape it, so you can see that the database includes NF2 data, as described in the first blog.
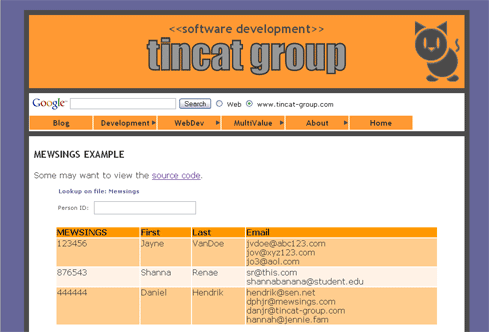
In practice, data modelers are influenced in their choices of a logical data model by their target DBMS. If the target database is based on the RM, the data modeler is less likely to select a property list for an entity (i.e. a multi-valued attribute requiring a new table in a SQL-DBMS). I have heard analysts convince users that a single-valued attribute would be best or at least appropriate "for this phase." It makes sense that if you have to split an attribute into a separate table, add in an ordering attribute and roll your own insert and ripple delete functions, you are simply less likely to even consider it. A technique sometimes used when lists are implemented in an RDBMS is to number using intervals that permit easy insertion in the midst of the list as long as you do not run out of numbers in the interval. There is then no hint in any given entry in the list what its ordinal position might be. If the first e-mail address were identified as address 10 and the second were numbered 20, another e-mail address could be inserted as 15. But, rather than avoiding ordered lists, you start seeing how common they are when you free your mind of the RM.
Even once you go through the work of implementing an ordered property list for an entity, the end-user might still be affected if you take your RM thinking to the UI. Think what the digital video editing tool user interface might be if it were to think like the RM. It is unlikely that this editing software holds these frames in a relational database but it shows the interface your users might want even if you did have a relational database backing an ordered property list. Now don't forget, software developers are users too. The DBMS APIs they use can make a significant difference.
Some...might think I'm about to confuse the data model with a representation.
Some readers around the world (I was thrilled to have readers from every continent except Antartica this past week with the first blog) might think I'm about to confuse the data model and the representation. I'm not. I am laying the groundwork for examining the definition and use of a data model. What is the relationship between a data model and the API that developers use in working with a DBMS? If we can have ordered lists and perform ripple deletes no matter what data model we are using, then what is my point? It has to do with the title of this blog—between the developer and the database, who did what work; who ordered a list of properties? For flexibility or productivity, does it make a difference who ordered the ripple delete?
Monday, January 09, 2006
Is Codd Dead?
Time Magazine issued a cover in 1966 asking "Is God Dead?" This is not the first time the name "Codd" has replaced "God" in a phrase, but in this case it is not for the purpose of comparison. In this blog, I will dare to question some of Codd's legacy including some of the dogma passed along in college database textbooks today.

E.F. (Ted) Codd died in 2003 leaving a significant contribution. Codd is often called the father of relational theory. His 1970 ACM paper A Relational Model of Data for Large Shared Data Banks (E. F. Codd, Communications of the ACM, v.13 n.6, p.377-387, June 1970) is a significant industry milestone.
In this paper, Codd discusses what he sees as the advantages in modeling data by use of mathematical relations compared to mathematical graphs of trees or networks.
Relations are often represented as tables of rows and columns. Trees are often visualized as nested folders and documents. The network graph, seen by Codd as overly complex and a cause of some of the problems he was addressing, can be visualized as a web. While a web, or directed-graph, might be a more complex mathematical structure than a relation, I predict that this data model might just catch on anyway (wink).
There are many viable models for data. Each has its advantages and disadvantages. This blog will not be about right and wrong as much as better and worse approaches. I'm a practitioner dabbling in theory in order to help improve the practice and not the other way around.
My advice is this: Stop normalizing your data. Stop removing all repeating groups.
Codd also introduces the term "normalize" to refer to removing nonsimple domains, such as lists or tables of data often referred to as "repeating groups." He is very clear in this paper that a relation could include repeating groups, but that normalizing it would make the data model simpler for some purposes.
The simplicity of the array representation which becomes feasible when all relations are cast in normal form is not only an advantage for storage purposes but also for communication of bulk data between systems which use widely different representations of data. (Codd, p. 381)
Anyone communicating bulk data by way of XML or JSON will recognize that we have different issues to solve today than we had in 1970. The rise of XML with its associated unnormalized data model is part of the impetus for what will likely be significant changes on the database landscape.
My advice is this: Stop normalizing your data. Stop removing all repeating groups. Note that I am using the original description of normalization from this paper. This meaning of normlization was later termed, or at least rolled into the term, "First Normal Form" or 1NF. The higher normal forms, such as BCNF, include laudable work with functional dependencies, but all are defined to first require normalization. There is definitely some good that can be salvaged from this normalizing debacle of the past few decades, but we must first ditch the requirement for data to be normalized, placed in 1NF, stripped of repeating groups. I will refer to relations that are not normalized, as others have, as NF2 for Non-First Normal Form.
Id: 123456
First: Jayne
Last: VanDoe
Email: jvdoe@abc123.com
jov@xyz123.com
jo3@aol.com
Id: 123456 First: Jayne Last: VanDoe Id: 123456 Email: jvdoe@abc123.com Id: 123456 Email: jov@xyz123.com Id: 123456 Email: jo3@aol.com
In this way you will model entities, such as the person above, with their dependent properties, such as the list of e-mail addresses. You only need to remove lists from your model, thereby going from the first example to the second above, if you are using tools that require it. Given that SQL-92 requires it, that is a big if. There are other viable, time-tested NF2 options, however.
Don't be fooled— there is no mathematical requirement to normalize data.
But the Relational Model (RM) is based on mathematics, right? Mathematics is precise. What part of the argument for the RM is amiss? Don't be fooled—there is no mathematical requirement to normalize data. Mathematics provides a means for modeling propositions to be handled in software, presented to end-users, passed as messages, or stored on secondary storage devices. The RM is a mathematical model. It is a model. Models are not the real thing. Models are often anorexic versions of the real thing. The mathematics of the relational model is sound, but the process of determining what this model should be used for is flawed.
The RM has been useful, but not as useful as some pre-relational models, in my opinion. Post-relational models of data for messages, such as those mentioned above, look very much like pre-relational models. I am hoping for a return to best practices for data models, whether or not the theory keeps up. I would, of course, prefer that theory be better aligned with excellent practices. Many pre- and post-relational tools use an NF2 model.
You are likely familiar with RDBMS products, often referred to as relational databases. Purists might prefer these be called SQL-DBMS products since SQL does not promote a pure relational model. I will use this column to dispel what I think to be myths that have helped SQL and the relational model rise to become king of the hill for a couple of decades. While this introductory column is admittedly not meaty, I will delve into this further and provide working examples in the coming weeks.
While I have not yet experimented with any XML DBMS tools, I have been working with one NF2 model, often referred to as the MultiValue (MV) or Pick® data model, for over a decade. This is not the only such model, but one with which I am comfortable, so I will introduce it here and use it in future illustrations and implementations.
Putting the RM and MV side-by-side while wearing both a technical and business woman's hat is what prompted me into further exploration of why the MV data model seems to yield higher productivity for developers, greater flexibility for changes over time, and lower risk of project failure. This was particularly perplexing when I started researching the topic because the RM was developed to help improve database maintenance. While the RM addresses some maintainability issues better than MV, MV seems more flexible in many respects. There are different risks and benefits associated with each approach.
Products employing an MV or NF2 data model include the IBM U2 products, Temenos jBASE, Revelation OpenInsight, Raining Data D3, Northgate Reality, EDP Plc UniVision, Ladybridge Systems OpenQM, and InterSystems Caché. There are other viable functional data model implementations with which I am less familiar, such as Berkeley DB from Sleepycat Software and other products marketed as embedded databases. This is definitely not a small niche market.
OpenQM is an open source implementation, so I will use that for my examples in future blogs. I will be the first to admit that MV isn't new, and although various flavors have tools to make it prettier, it typically doesn't look new. It is unlikely to wow you at first glance, but it often grows on developers quickly with its big bang for the buck results and maintainability. The same principles can be applied to many environments, however, and will typically not be specific to MV tools.
I would like to see the industry start with an NF2 model and move it forward rather than squeeze more out of SQL, as has been attempted with the more recent SQL standards. SQL will be with us for many years, but it is time to make an abrupt cut away from it wherever feasible.
Codd will long be remembered for some very innovative work in the area of database theory. But, yes folks, Codd is dead.
